Word Error Rate berättar om taligenkänningssystemets noggrannhet
Word Error Rate (WER) är ett vanligt använt mått för att utvärdera noggrannheten hos taligenkänningssystem. WER mäter hur många fel ett taligenkänningssystem gör när det konverterar tal till text. WER beräknas genom att jämföra den igenkända texten med originalmanuskriptet och identifiera skillnader som tillagda, saknade eller feligenkända ord.
WER beräknas enligt följande:
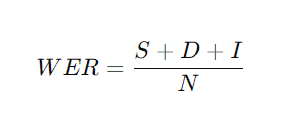
- S är felaktigt ersatta ord (Substitutions),
- D saknar ord (Deletions),
- I är infogade ord (Insertions),
- N är antalet ord i originaltexten.
I praktiken kan WER användas för att utvärdera taligenkänningssystemets prestanda i olika användningssituationer. Det är ett nyckelmått när man utvecklar och förbättrar automatiska taligenkänningssystem, som även används som hjälpmedel i till exempel Spokens undertextnings- och transkriptionstjänster.
Ju lägre WER, desto mer exakt är taligenkänningssystemet. Att minska WER är därför ett primärt mål för företag och forskare som fokuserar på att utveckla taligenkänningsteknik.
Whisper och WER-värden för olika språk
På Spoken använder vi OpenAI:s Whisper-taligenkänningsmodell för taligenkänning, där WER-värdena varierar beroende på språk. I engelsk taligenkänning är WER vanligtvis den lägsta och därmed den bästa, tack vare den stora mängden data som finns tillgänglig och det faktum att modellen har optimerats för det engelska språket.
För engelska kan WER vara så låg som fem till sex procent. I svensk, norsk och dansk taligenkänning är WER-värdena något högre än så, runt åtta till tio procent. På finska kan WER vara ännu högre än så, runt 10-12 procent, på grund av det finska språkets unika struktur och morfologi, vilket innebär särskilda utmaningar för taligenkänningssystem.
Denna jämförelse visar att medan Whisper är mycket effektivt för många språk, har språkstruktur och datatillgänglighet en betydande inverkan på WER.